
Die verschiedenen Kategorien und Prozessschritte des Machine Learnings
Machine Learning gilt als Teilgebiet der Künstlichen Intelligenz – der Wissenschaft, Computer mit intelligenten Verhalten zu programmieren. Und somit der Schlüssel in die Welt der Automatisierung und Roborter. Meiner Meinung nach Grund genug, sich einmal ein wenig genauer damit zu beschäftigen.
In Rahmen des Trendscouting Teams haben wir bereits in zwei vorherigen Artikeln Machine Learning (Teil 1, Teil 2) unter die Lupe genommen. Dort haben wir uns insbesondere mit dem k-means-Algorithmus beschäftigt. Hier möchte ich aber nochmal einen Schritt zurückgehen und die allgemeine Vorgehensweise bei Machine Learning Algorithmen erläutern. In meinem nächsten Artikel beschreibe ich einen weiteren Algorithmus, Neuronale Netze, genauer.
Bei Machine Learning Algorithmen gibt es einen grundlegenden Unterschied zwischen einem „unsupervised“ (deutsch: unüberwachten) und einem „supervised“ (überwachten) Learning Algorithmus.
Bei einem „unsupervised“ Learning sucht der Algorithmus in vorhandenen Daten nach neuen Mustern, die wir vorher noch nicht kennen. In unserem letzten Beispiel haben wir versucht, Kunden in verschiedene Segmente einzuteilen, ohne allerdings vorzugeben anhand von welchen Merkmalen wir diese Einteilung vornehmen möchten. Das war ein typisches Beispiel eines Clustering-Algorithmus, wodurch das Prinzip eines „unsupervised“ Algorithmus gut erklärt wurde. Folgende Grafik veranschaulicht dies nochmal.
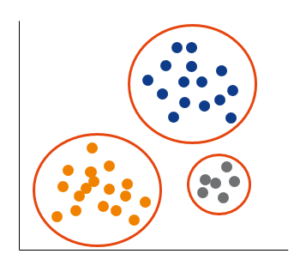
Beispiel „unsupervised learning“
Bei einem „supervised“ (überwachtes) Learning hingegen kennt man bereits das Kriterium (Zielvariable), anhand dessen man die Daten einteilen möchte. Daher auch der Name „überwachter Prozess“. Hier versucht man ein Modell zu bauen, das den Wert dieser Zielvariable vorhersagt. Zu dieser Kategorie zählen Klassifizierungsalgorithmen und Regressionsanalysen. Der Unterschied liegt darin, dass es bei der Klassifizierung um eine Entscheidung zwischen zwei Kategorien (ja/nein, wahr/falsch, rot/grün, etc.) geht, wobei es bei der Regression um einen Zahlenbereich geht, hier möchte man also eine Zahl vorhersagen.
Ich habe mir ein Klassifizierungsbeispiel überlegt, um „supervised“ Learing genauer zu erläutern. Und zwar möchte ich ein Modell bauen, das anhand von Kundenmerkmalen vorhersagt, zu welchem der beiden Klassen ein (neuer) Kunde gehört.
1: Kunde zahlt Kredit pünktlich zurück
oder
0: Kunde zahlt Kredit nicht pünktlich zurück.
Wir verfügen also über historische Daten, die diese Zielvariable bereits beinhalten und nutzen diese, um ein Modell zu bauen, das diese Zielvariable zukünftiger Kunden vorhersagt. Dafür teilen wir die vorhandenen Daten in Trainings- und Testdaten ein.
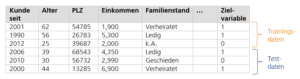
Beispielsdatenset
Mit Hilfe der Trainingsdaten bauen wir das Modell und anhand der Testdaten testen wir das gebaute Modell auf dessen Allgemeingültigkeit. Wir tun also so, als wüssten wir nur bei den Trainingsdaten, ob ein Kunde den Kredit pünktlich zurückzahlt (1) oder nicht (0). Bei den Testdaten ignorieren wir diese Zielvariable und sagen diese mithilfe unseres erstellten Modells vorher. Unsere Testdaten dienen also sozusagen als zukünftige Kundendaten, von denen wir das Alter, die PLZ, das Einkommen, etc. kennen und vorhersagen möchten, ob der Kunde den Kredit pünktlich zurückzahlen wird (1) oder nicht (0). Die Qualität unseres Modells können also anhand dieser Testdaten messen, indem wir den vorhergesagten Wert der Zielvariable mit dem vorhandenen Wert der Zielvariable vergleichen.
Dieser Prozess ist gut an folgender Grafik von Prof. Roßbach zu verdeutlichen. Dadurch wird sichergestellt, dass das erstellte Modell auch in der Realität funktioniert. Dies ist nicht gewährleistet, würde man das gleiche Datenset zur Erstellung und zum Testen des Modells nutzen.
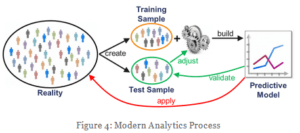
Trainings- und Testdaten Quelle: http://blog.frankfurt-school.de/machine-learning-modern-data-analytics-artificial-intelligence/?lang=de
Dadurch vermeidet man, dass das Model nicht unter „Underfitting“ oder „Overfitting“ leidet. „Underfitting“ bedeutet, dass das erstellte Modell zu allgemein und „simple“ ist und zu einer hohen Fehlerquote führt. „Overfitting“ hingegen bedeutet das Gegenteil – das Model ist zu stark an Ausreißern oder nicht-repräsentativen Daten im Trainingsset orientiert und somit zu komplex für die „reale Welt“. In unserem Beispiel bedeutet das also, dass das Modell bei der Anwendung der Testdaten oft den falschen Wert der Zielvariable vorhersagt. Ziel ist es die Mitte zwischen „Over-“ und „Underfitting“ zu finden, indem man das Modell durch verschiedene Parameter anpasst.
In meinem nächsten Artikel werde ich neben den k-Means Algorithmus in unserem letzten Artikel auf den Algorithmus von Neuronalen Netzen eingehen.
Quellen:
http://oliviaklose.azurewebsites.net/machine-learning-2-supervised-versus-unsupervised-learning/
https://towardsdatascience.com/the-7-steps-of-machine-learning-2877d7e5548e
Diese Themen interessieren uns
Lean and Secure Decentralized Delivery-versus-Payment (DvP) for Securities Settlement

22. Dezember 2023
FinTech Innovationen in Asien – Ein Blick auf das FinTech Festival in Singapur

3. November 2023