
Trendscouts nehmen Machine Learning unter die Lupe: Kundensegmentierung (Teil 1)
Vom mobilen Sprachassistenten bis hin zur autonomen Einparkhilfe – Machine Learning findet immer mehr Anwendungsbereiche in unserem Alltag. Auch lesen wir immer häufiger, dass die Finanzindustrie durch den Einsatz von Machine Learning profitieren will. Aber wie kann Machine Learning uns eigentlich unterstützen? Und was passiert genau in der Blackbox Machine Learning? Als Trendscouts beschäftigen wir uns mit solchen Fragen und tragen die Antworten darauf in die DZ BANK Gruppe.
Effizientere Kundensegmentierung durch Machine Learning
Ein Anwendungsfall von Machine Learning, der auch für die Finanzindustrie relevant ist, ist die Kundensegmentierung und die damit einhergehende Produktpersonalisierung. Ziel der Kundensegmentierung ist die effektive Kundenbetreuung. Hier werden Kunden möglichst gezielt adressiert bzw. ähnliche Kunden zusammengefasst und gebündelt angesprochen. Diese Kunden werden dabei nach bestimmten Merkmalen, wie zum Beispiel Branche, Standort oder Unternehmensgröße, gruppiert.
Aktuell wird in Finanzinstituten häufig nur nach einem Merkmal segmentiert – mit zunehmender Individualisierung im Sinne einer steigenden Zahl von Merkmalen wird dieser Vorgang immer komplexer. Genau diese Komplexität ist auch laut IT-Finanzmagazin der Grund, warum im Zeitalter von Mass-Customization in Finanzinstituten immer noch „meist relativ einfache Segmentierungsansätze und -merkmale“ für die Kundensegmentierung gewählt werden.
Mustererkennung durch Clustering-Algorithmen
Wenn es darum geht in einer Datenmenge Muster in Form von Ähnlichkeiten zu erkennen, kann uns Machine Learning unterstützen. Mustererkennung, wie zum Beispiel die Unterscheidung zwischen roten und blauen Lego-Bausteinen, ist eine der ersten Fähigkeiten, die wir als Kinder lernen. Aber wie können wir einer Maschine diese Fähigkeit beibringen? Tatsächlich hat Machine Learning wenig mit menschlichem Intellekt zu tun. Vielmehr folgen die Maschinen für bestimmte Aufgaben einer Art Rezept – einem Algorithmus. Eine Folge von Anweisungen, die eine Maschine ausführt, um ähnliche Objekte zu gruppieren, nennt man Clustering-Algorithmen.
Clustering-Algorithmen sind in der Lage, Objekte nach ähnlichen Eigenschaften zu gruppieren. Stellen Sie sich vor, Sie stricken gerne und gründen ein Start-Up mit dem Sie in Handarbeit gefertigte Pullover verkaufen. Sie sind schon sehr erfolgreich und haben bereits zehn Kunden. Zu jedem Kunden kennen Sie die Körpergröße und das Gewicht. Da Sie nicht für jeden Kunden eine individuelle Größe stricken möchten, aber trotzdem der Pullover allen gut passen soll, entscheiden Sie sich den Pullover in drei verschiedene Größen herzustellen. Jetzt stehen Sie aber vor der Frage, wie Sie am besten ihre Größen wählen. Wie fassen Sie jetzt also ihre Kunden am besten zu Pullover-Größen zusammen? Diese Frage kann ein Clustering-Algorithmus beantworten.
Segmentierung nach dem Clustering-Algorithmus k-Means
Genauso wie Clustering-Algorithmen – wie in unserem Beispiel – in der Lage sind, aus einer Menschenmenge drei Pullover-Größen zu identifizieren, können sie auch Kunden in Segmente einteilen. Ein Clustering-Algorithmus, der häufig zur Kundensegmentierung genutzt wird, aber selten genannt wird, ist der sogenannte k-Means-Algorithmus. Dieser Algorithmus bildet aus einer Menge ähnlicher Objekte eine vorgegebene Anzahl an Gruppen. Das bedeutet, dass er aus einem Kundendatensatz („eine Menge ähnlicher Objekte“) drei Pullover-Größen („eine vorgegebene Anzahl an Gruppen“) bilden kann.
Die vorgegebene Anzahl an Gruppen wird durch das „k“ repräsentiert. Wenn ich die Datenmenge in drei Segmente unterteilen möchte, wäre k = 3 und man könnte auch von dem „3-Means-Algorithmus“ sprechen. Da der Algorithmus aber für jede beliebige Anzahl an Segmenten gleich funktioniert, sprechen wir pauschal von k Gruppen und daher dem k-Means-Algorithmus.
Mean bedeutet auf Deutsch Durchschnitt. Beim k-Means-Algorithmus wird in jeder Wiederholung die Durchschnittsposition aller Datenpunkte innerhalb eines Segmentes berechnet. Diese Durchschnittsposition wird dann im nächsten Schritt als Zentrum des Segmentes verwendet. Die Segmente, die beim k-Means-Algorithmus gefunden werden, können also wie Kreise verstanden werden, deren Mittelpunkt die Durchschnittsposition aller Punkte in diesem Segment ist.
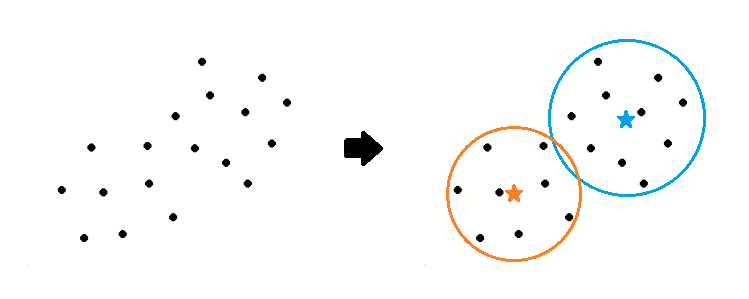
Der Name des Algorithmus ergibt sich also daher, dass die Kunden in eine Anzahl k vorgegebene Gruppen (z.B. k=2) durch eine Durchschnittsberechnung (engl. mean) eingeteilt werden. Dies geschieht im Grunde genommen nach den folgenden vier Schritten:
- Für jedes Segment wird, wie bei einem Kreis, ein Mittelpunkt festgelegt.
- Jeder Kunde wird dem näheren Segmentmittelpunkt zugeteilt.
- Der Segmentmittelpunkt wird als Durchschnittsposition aller Kunden im Segment neu ausgerichtet.
- Wederholen von Schritt 2 und Schritt 3 bis im Schritt 3 keine Änderung eintritt.
War Ihnen diese Erklärung zu oberflächlich? Dann schauen Sie doch mit uns unter die Haube des k-Means-Algorithmus im Teil 2 dieses Artikels!.
Fazit
Machine Learning wird auch für die Finanzindustrie immer relevanter. Daher ist es auch für uns wichtig, grundlegend zu verstehen, wie Machine Learning eigentlich funktioniert. In diesem Artikel habe ich erläutert, wie uns Machine Learning in der Kundensegmentierung unterstützen kann. Wenn Sie Anwendungsfälle von Machine Learning kennen, deren technische Hintergründe Sie gerne verstehen wollen, hinterlassen Sie doch gerne einen Kommentar. Ich freue mich auf ihre Fragen und Anregungen!
Quellen
Business Science: Customer Segmentation Part 1: k-Means Clustering. http://www.business-science.io/business/2016/08/07/CustomerSegmentationPt1.html (03.08.2017)
Gisler, Claudio: Neue Möglichkeiten für die Kundensegmentierung bei Banken. https://www.der-bank-blog.de/neue-moeglichkeiten-kundensegmentierung/marketing/27801/ (30.07.2017).
Grewal, Ami: Auf dem Vormarsch: Machine Learning und Artificial Intelligence. https://blog.gft.com/de/2017/03/03/machine-learning-und-artificial-intelligence/ (30.07.2017).
Ng, Andrew: Clustering – kMeans Algorithm. https://www.youtube.com/watch?v=hDmNF9JG3lo (03.08.2017).
Peters, Anja: Befragung: Kundensegmentierung in Banken und Sparkassen – heute und morgen. https://www.it-finanzmagazin.de/befragung-kundensegmentierung-in-banken-und-sparkassen-heute-und-morgen-25548/ (03.08.2017).
Diese Themen interessieren uns
Lean and Secure Decentralized Delivery-versus-Payment (DvP) for Securities Settlement

22. Dezember 2023
FinTech Innovationen in Asien – Ein Blick auf das FinTech Festival in Singapur

3. November 2023
Schöner Artikel!
Eine sehr gute Einführung in Machine Learning ist auch die (englischsprachige) Serie Machine Learning is Fun!
https://medium.com/@ageitgey/machine-learning-is-fun-80ea3ec3c471
Da geht es allerdings vorrangig um neuronale Netze. Die könnte man in d